
Структура программы на языке Паскаль
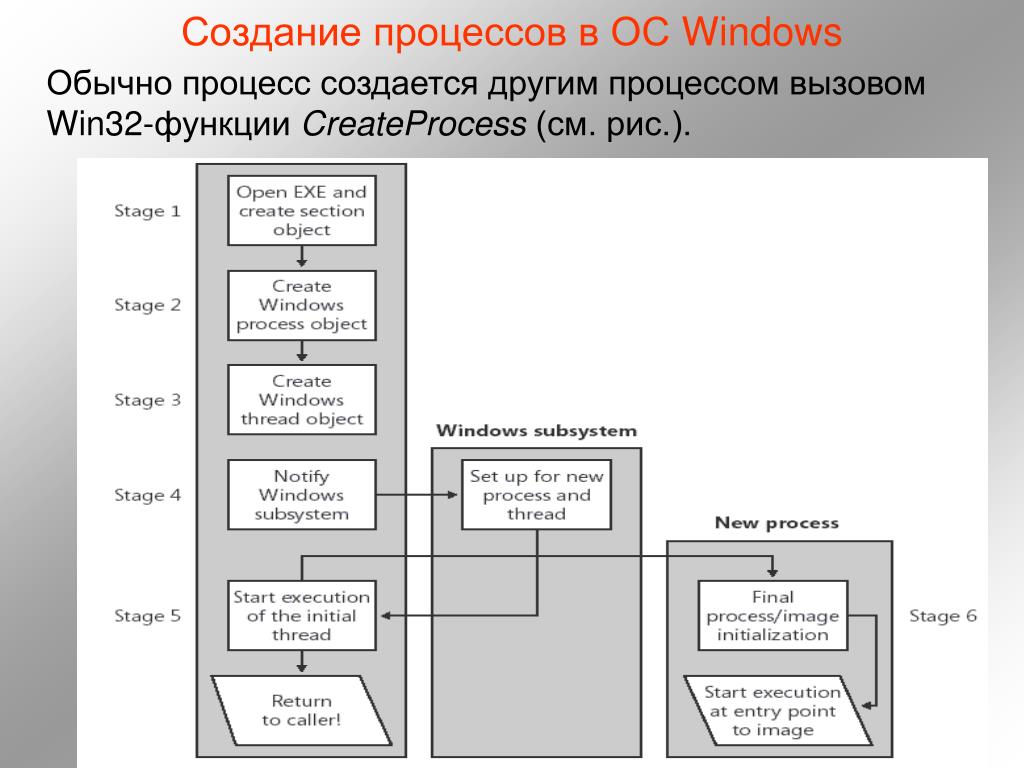
Прежде чем самостоятельно писать программы, разберем ее структуру на примере. Ниже приведен код программы, которая вычисляет сумму двух чисел и выводит ее на экран.
program primer1;
var х,у,zinteger; { описание переменных }
begin { начало программы }
х = 3; { установка значения х }
у = 5; { установка значения у }
z = х + у; { вычисление суммы }
write(z); {вывод результата вычисления на экран }
end. { конец программы }
Заголовок программы
Текст программы начинается со слова program. После него записывается имя программы. Данная строка носит информативный характер и ее можно не писать.
Раздел описания переменных
Раздел программы, обозначенный служебным словом var, содержит описание переменных с указанием их типов. Они используются для хранения исходных данных, результатов вычисления и промежуточных результатов.
В нашем примере переменные с именами X и Y используются для хранения исходных данных. Переменная с именем Z используется для хранения результата вычислений.
Переменные одного типа можно указать в одной строке через запятую. После ставится двоеточие и указывается тип, к которому принадлежат переменные. Тип определяет допустимый диапазон значений.
Принадлежность переменной к типу integer означает, что она может хранить только целые числа. Если требуется хранить действительные (дробные) числа, тогда используется тип real.
Тело программы
Все что находится между служебными словами Begin и end — тело программы. Здесь записываются основные команды.
Оператор присваивания значений переменным имеет следующую структуру: переменная := выражение
Значок : = (двоеточие, равно) читается как «присвоить». Умножение обозначается символом * (звездочка), деление — символом (слеш).
Вывод результата выполняет команда write или print.
![]()
Запланированные задания
В Windows 8/8.1 планировщик и перейдите в раздел Библиотека планировщика заданий — Microsoft — Windows – TaskScheduler.
В Windows 10 эти задания спрятаны из планировщика, чтобы люди не мешали обслуживанию ОС, отключая задания. Однако все они есть в реестре, поэтому особо талантливые пользователи смогут воспрепятствовать обслуживанию при желании.
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\Schedule\TaskCache\Tree\Microsoft\Windows\TaskScheduler
Внизу списка вы видите то самое задание Regular Maintenance, время ежедневного запуска которого можно настроить в панели управления
Обратите внимание, что в планировщике вы можете изменить расписание запуска, например, на еженедельное. Однако делать это вовсе необязательно, ибо в итоге все упирается в бездействие ПК
Если вы запустите задание Manual Maintenance, система выполнит тот же самый набор задач по обслуживанию, что и при запуске задания по расписанию. Отличие в том, что ваше взаимодействие с системой не прервет процесс оптимизации, поскольку вы сами запустили его.
Отключенное задание Idle Maintenance любопытно тем, что система сама включает его при выполнении ручного или автоматического обслуживания. Однако других подробностей о нем мне выяснить не удалось.
Задание Maintenance Configurator, судя по нескольким триггерам, определяет список задач, обслуживающих систему.
помогите с правильным ответом пожалуйста .
1)Производительность работы компьютера зависит от: Выберите один ответ: a. напряжения питания; b. типа монитора; c. частоты процессора; d. быстроты нажатия на клавиши.
2)Процессор обрабатывает информацию: Выберите один ответ: a. в двоичном коде; b. в текстовом виде. c. в десятичной системе счисления; d. на языке Бейсик; 3)Укажите устройства, не являющиеся устройствами ввода информации: Выберите один ответ: a. сканер. b. мышь; c. клавиатура; d. монитор; 4)Какое устройство оказывает вредное воздействие на здоровье человека? Выберите один ответ: a. клавиатура. b. монитор; c. принтер; 5)Во время исполнения программа находится: Выберите один ответ: a. на клавиатуре; b. в оперативной памяти; c. в буфере обмена; d. на жестком диске. 6)Наименьшим адресуемым элементом оперативной памяти является: Выберите один ответ: a. файл. b. байт; c. регистр; d. машинное слово 7)Массовое производство персональных компьютеров началось в: Выберите один ответ: a. 50-е гг; b. 90-е гг. c. 80-е гг; d. 40-е гг; 8)Чтобы процессор мог работать с программами, хранящимися на жестком диске, необходимо: Выберите один ответ: a. открыть доступ. b. загрузить их в оперативную память; c. вывести их на экран монитора; d. загрузить их в процессор; 9)Укажите верное высказывание: Выберите один ответ: a. компьютер состоит из отдельных модулей, соединенных между собой b. составные части компьютерной системы являются незаменяемыми; c. компьютер представляет собой единое, неделимое устройство; d. компьютерная система способна сколь угодно долго соответствовать требованиям современного общества и не нуждается в модернизации. 10)Общим свойством машины Беббиджа, современного компьютера и чело¬веческого мозга является способность обрабатывать: Выберите один ответ: a. текстовую информацию; b. числовую информацию; c. звуковую информацию; d. графическую информацию. 11)Свойством ПЗУ является: Выберите один ответ: a. хранить данные, не находящиеся все время в ОЗУ; b. вводить информацию. c. переносить информацию; d. обрабатывать информацию;
1. Производительность работы компьютера зависит от напряжения питания и частоты процессора. Если тебя будут уверять, что питание тут не при чем, то можешь смело переводиться в другую школу \ универ или где ты там
2. Процессор обрабатывает информацию в двоичном коде. Точно не уверен, но вроде бы в нулях и единицах
3. Укажите устройства, не являющиеся устройствами ввода информации: монитор. Он ВЫВОДИТ информацию
4. Какое устройство оказывает вредное воздействие на здоровье человека? Опять же монитор. Зрение портит.
5. Во время исполнения программа находится в оперативной памяти
6. Наименьшим адресуемым элементом оперативной памяти является байт
7. Массовое производство персональных компьютеров началось в 80-е гг Точно не уверен.
8. Чтобы процессор мог работать с программами, хранящимися на жестком диске, необходимо загрузить их в оперативную память. Но опять же, точно не уверен.
9. Укажите верное высказывание: компьютер состоит из отдельных модулей, соединенных между собой
10. Общим свойством машины Беббиджа, современного компьютера и чело¬веческого мозга является способность обрабатывать числовую информацию
11. Свойством ПЗУ является хранить данные, не находящиеся все время в ОЗУ
1)С 2)А 3)d 4)b 5)b 6)вообще хз байт наверное 7)эт можн в гуглу найти 8)b или d 9)тут тож боюсь не правильно ответить как в учебнике написано такой ответ и надо выберать10)b 11)a
Источник
7.1.4. Подходы к обработке ошибок¶
При написании кода необходимо предусматривать, что в определенном месте программы может возникнуть ошибка и дополнять код на случай ее возникновения.
Существует два ключевых подхода программирования реакции на возможные ошибки:
-
«Семь раз отмерь, один раз отрежь» — LBYL (англ. Look Before You Leap);
-
«Легче попросить прощения, чем разрешения» — EAFP (англ. «It’s Easier To Ask Forgiveness Than Permission»).
-







В Листинге 7.1.2 приведен пример сравнения двух подходов.
Листинг 7.1.2 — Псевдокод функций, использующих разные подходы к обработке ошибок: «Семь раз отмерь, один раз отрежь» и «Легче попросить прощения, чем разрешения»
Обе функции возвращают решение линейного уравнения и НИЧЕГО, если 'a' =
ФУНКЦИЯ найти_корень_1(a, b):
ЕСЛИ a не равно
ВЕРНУТЬ -b a
ИНАЧЕ
ВЕРНУТЬ НИЧЕГО
ФУНКЦИЯ найти_корень_2(a, b):
ОПАСНЫЙ БЛОК КОДА # Внутри данного блока пишется код, который
ВЕРНУТЬ -b a # потенциально может привести к ошибкам
ЕСЛИ ПРОИЗОШЛА ОШИБКА # В случае деления на 0 попадаем сюда
ВЕРНУТЬ НИЧЕГО
Подход «Семь раз отмерь, один раз отрежь» имеет определенные минусы:
-
проверки могут уменьшить читаемость и ясность основного кода;
-
код проверки может дублировать значительную часть работы, осуществляемой основным кодом;
-
разработчик может легко допустить ошибку, забыв какую-либо из проверок;
-
ситуация может изменится между моментом проверки и моментом выполнения операции.
Персональный, значит личный
Для начала определимся, что собой представляет ПК.
Современный компьютер – это многофункциональный прибор, который позволяет смотреть фильмы, слушать аудиокниги, рисовать, писать тексты, чертить чертежи или таблицы. Это лишь минимальная часть того, что он умеет. Его главное назначение – работа со всеми видами информации (получение, преобразование, сохранение, выдача). Есть стационарные модели (настольные) и переносные (портативные, карманные).
Персональный компьютер (ПК) разработан для пользования одного человека. Самый простой ПК содержит минимальные компоненты для выполнения основных функций. Исходя из того, что планирует пользователь, его можно сделать более функциональным и мощным.
Базовая комплектация
Чтобы компьютер работал, выполнял свои минимальные функции, нужны такие базовые компоненты:
- системный блок – основной блок прибора, в нем содержатся все внутренние устройства, которые управляют работой ПК;
- монитор – блок компьютера, на который выводится визуальная информация (символы, графика). Представлены ЖК мониторами и устаревшими ЭЛТ;
- мышь – блок, позволяющий подавать ПК команды. Курсор двигается по экрану, выбирая нужный объект для выделения«графически». Есть модели с дополнительными боковыми кнопками, несколькими колесиками. Производятся проводные варианты и без проводов;
- клавиатура – блок, позволяющий вводить информацию, в том числе команды, при помощи символов. Содержит 104 клавиши, плюс световая индикация и вспомогательные кнопки, в зависимости от модели. Есть проводные и беспроводные.
Интересно:
Мониторы часто выбирают, учитывая размер диагонали, разрешение и частоту обновления картинки.
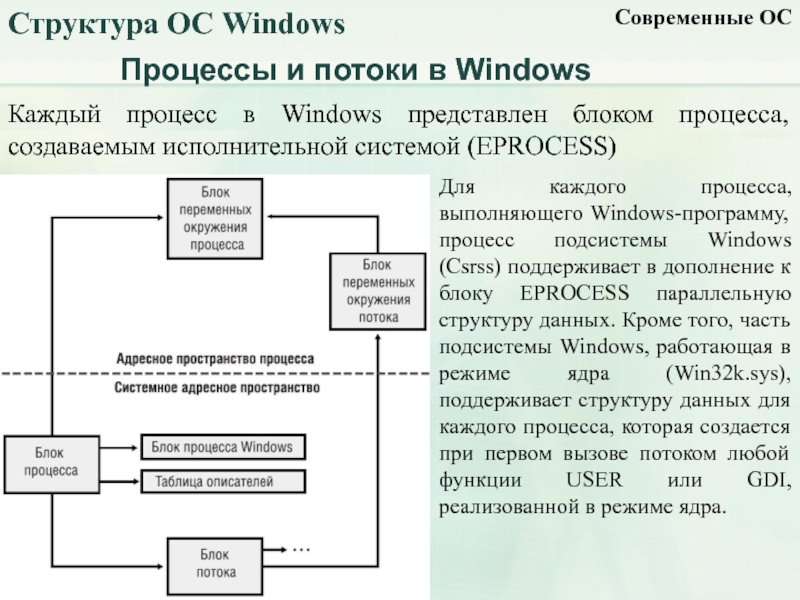
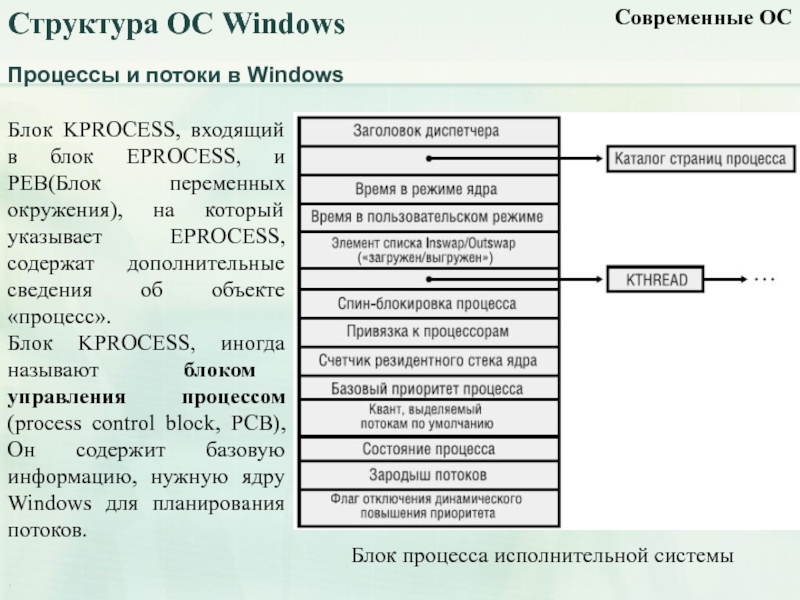
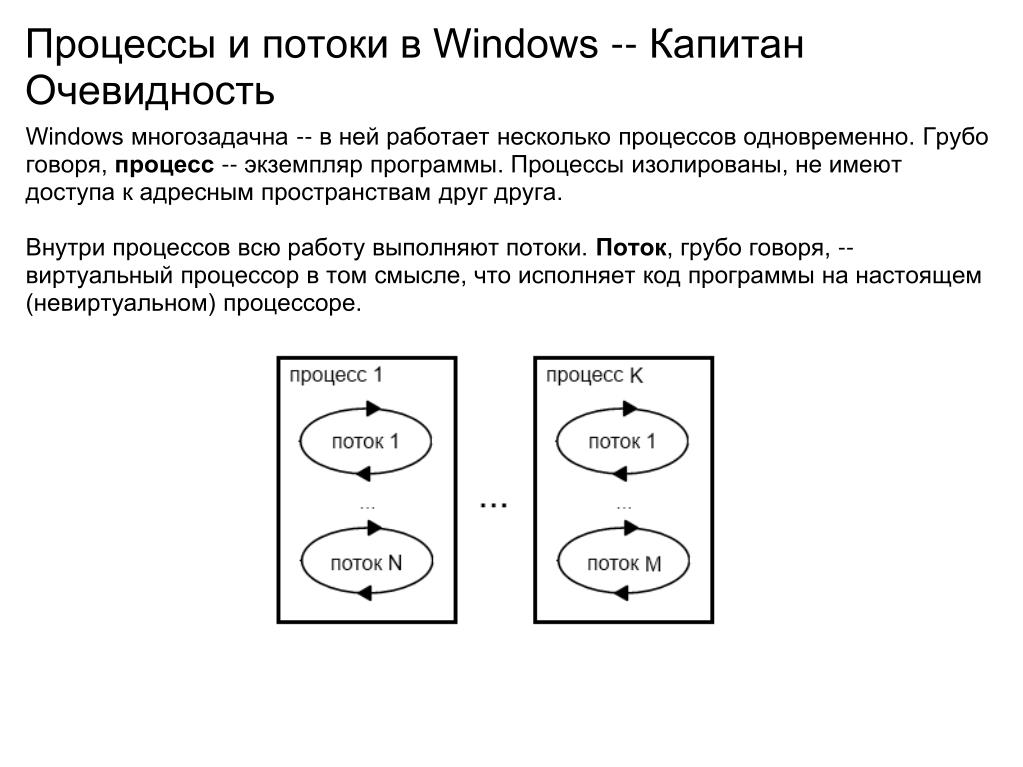
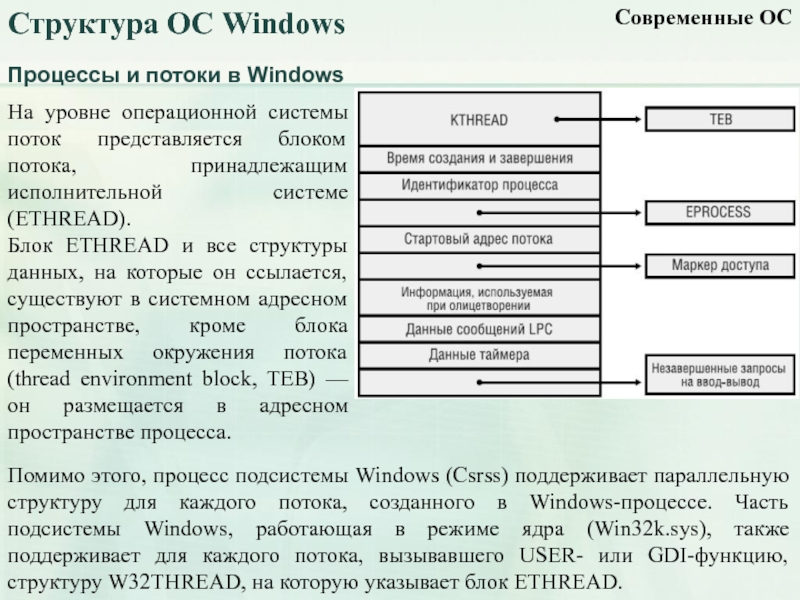
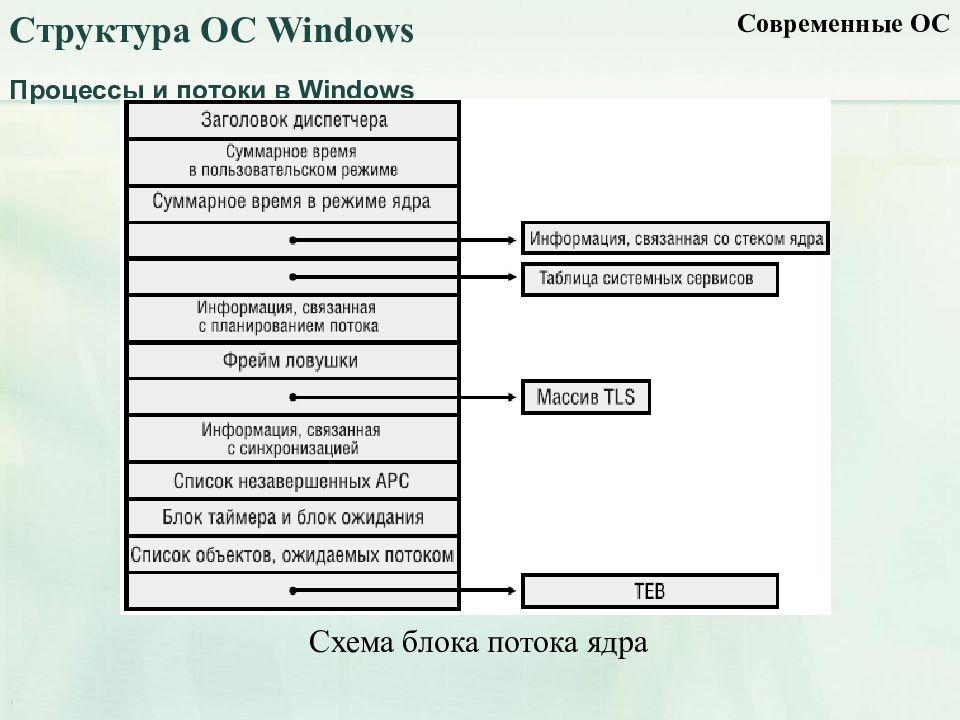
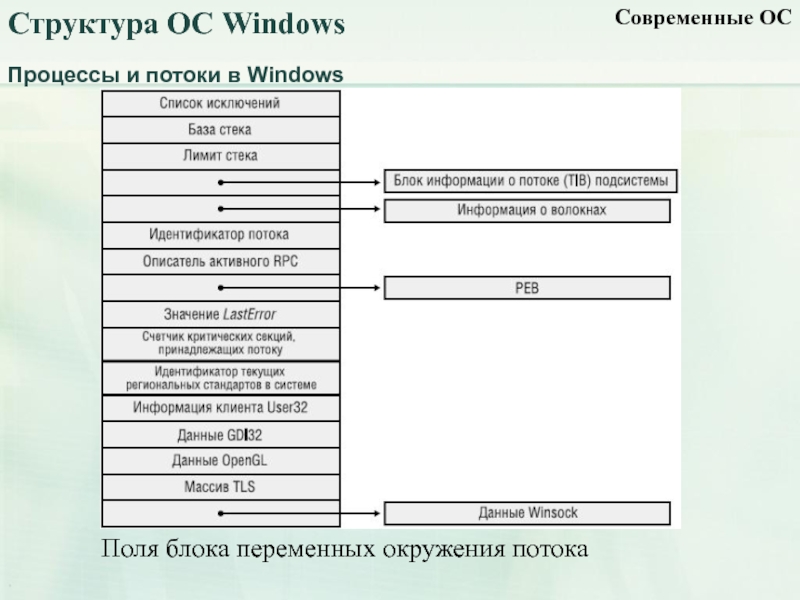
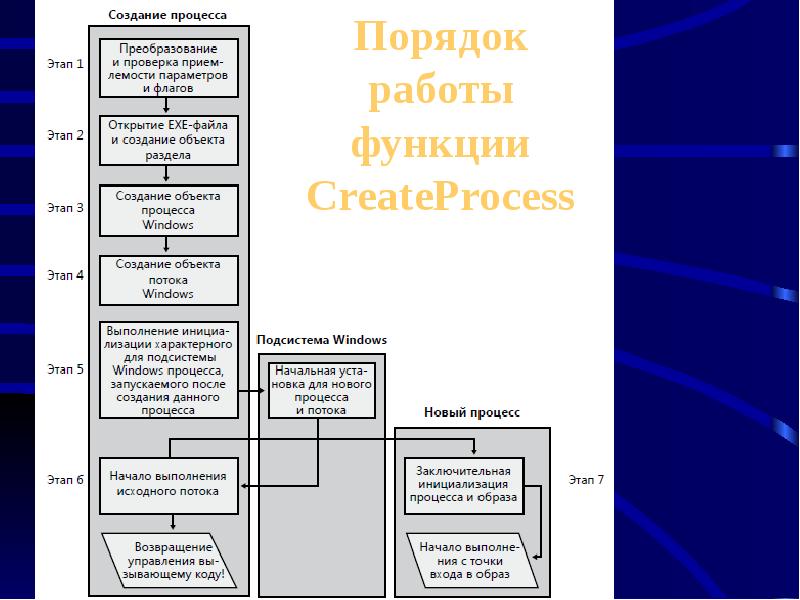
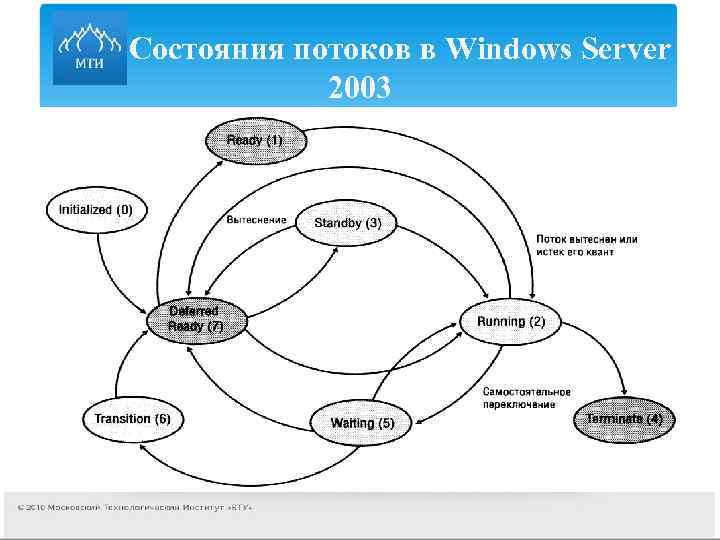
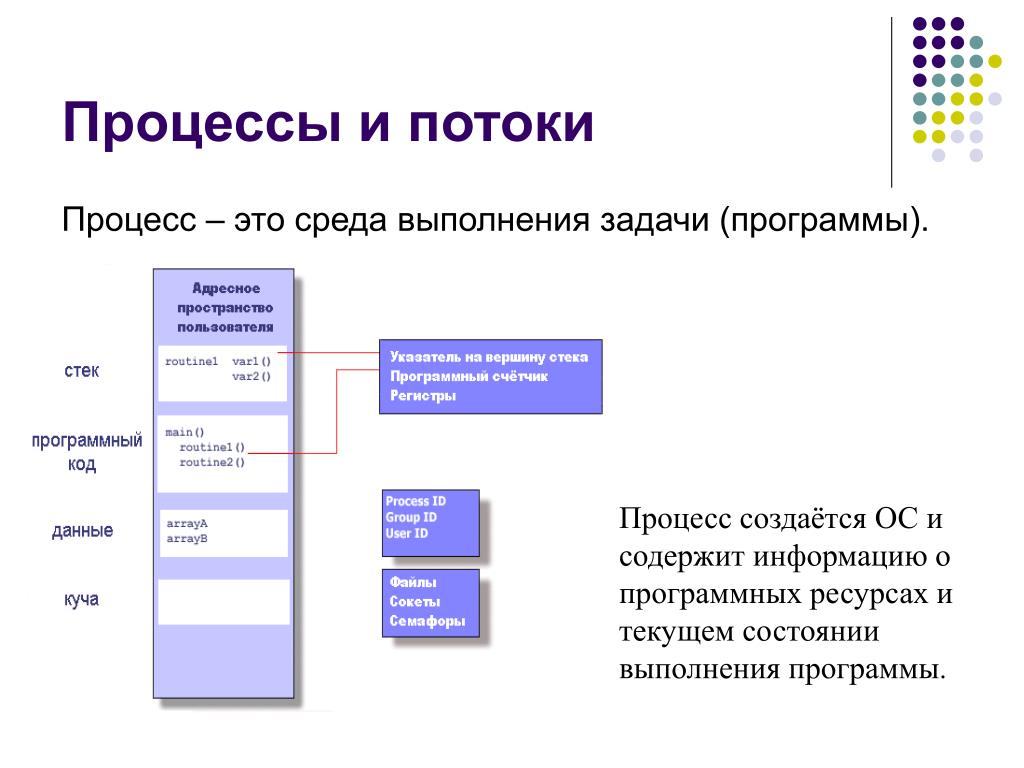
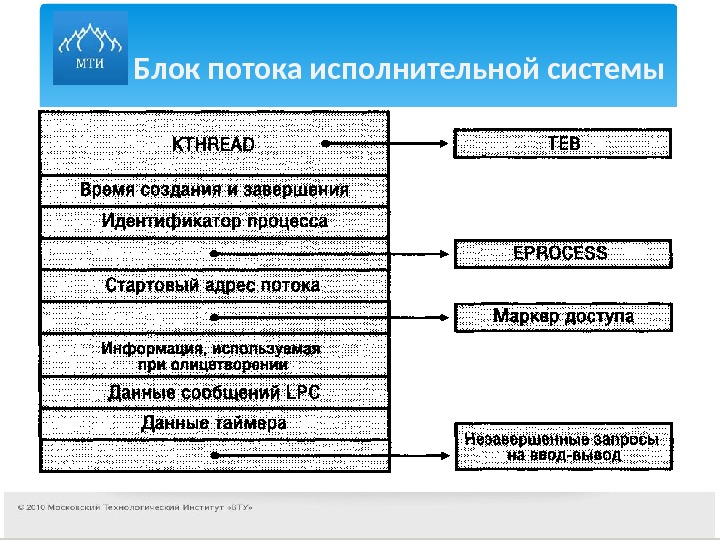
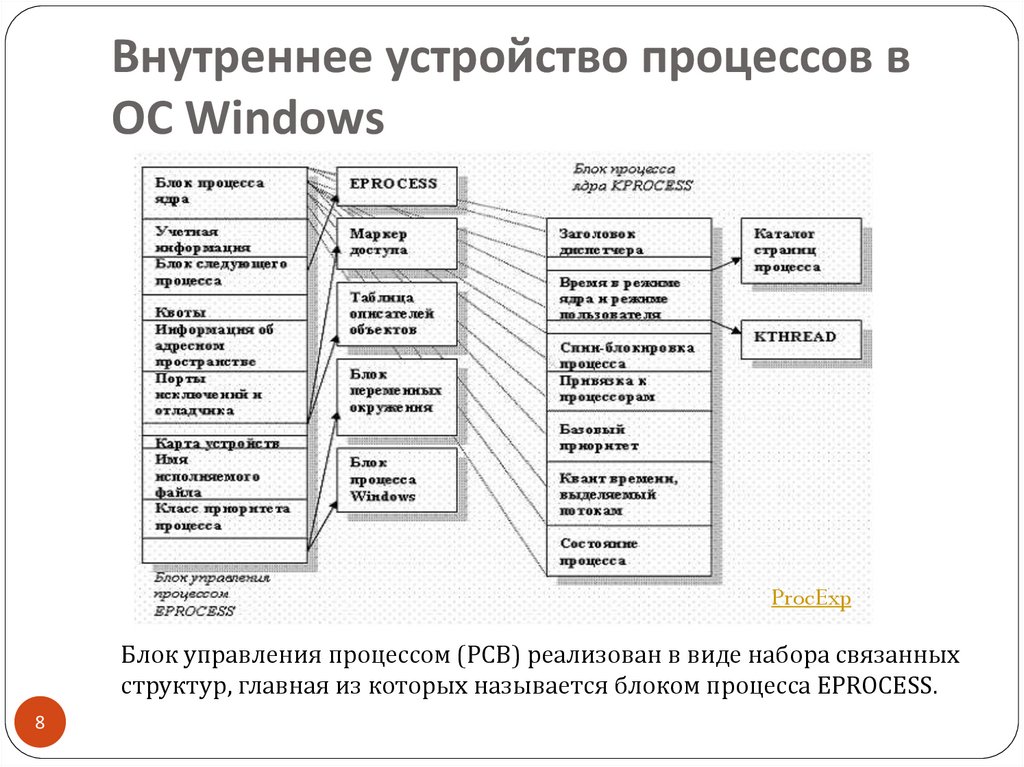
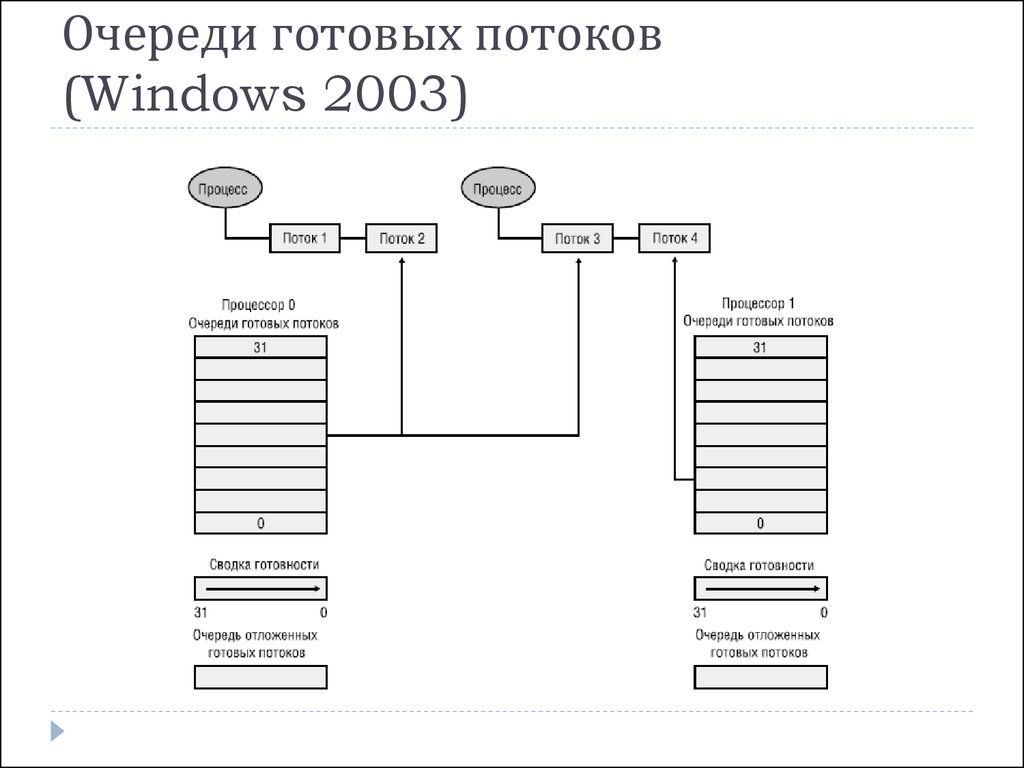
Волокна и планирование пользовательского режима
Потоки выполняются на центральном процессоре, а за их переключение отвечает планировщик ядра. В связи с тем что такое переключение это затратная операция. В Windows придумали два механизма для сокращения таких затрат: волокна (fibers) и планирование пользовательского режима (UMS, User Mode Scheduling).
Во-первых, поток с помощью специальной функции может превратится в волокно, затем это волокно может породить другие волокна, таким образом образуется группа волокон. Волокна не видимы для ядра и не обращаются к планировщику. Вместо этого они сами договариваются в какой последовательности они будут обращаться к процессору. Но волокна плохо реализованы в Windows, большинство библиотек ничего не знает о существовании волокон. Поэтому волокна могут обрабатываться как потоки и начнутся различные сбои в программе если она использует такие библиотеки.
Потоки UMS (User Mode Scheduling), доступные только в 64-разрядных версиях Windows, предоставляют все основные преимущества волокон при минимуме их недостатков. Потоки UMS обладают собственным состоянием ядра, поэтому они «видимы» для ядра, что позволяет нескольким потокам UMS совместно использовать процессор и конкурировать за него. Работает это следующим образом:
- Когда двум и более потокам UMS требуется выполнить работу в пользовательском режиме, они сами могут периодически уступать управление другому потоку в пользовательском режиме, не обращаясь к планировщику. Ядро при этом думает что продолжает работать один поток.
- Когда потоку UMS все таки нужно обратиться к ядру, он переключается на специально выделенный поток режима ядра.
Дополнительная информация
Когда я писал статью о извлечении аудио из видеофайла с помощью FFmpeg.exe, я думал об измерении времени выполнения команды. Я использовал приведенный выше скрипт для измерения времени, необходимого для извлечения аудио MP3 из файла фильма, используя инструмент командной строки FFmpeg.exe.
Первая партия включала эту командную строку:
ffmpeg -i "C: \ Movies \ Movie.mp4" -ss 01:20:00 -t 00:00:20 -кодек: libmp3lame -ab 128000 "D: \ output-1.mp3"
Вторая партия включала эту командную строку:
ffmpeg -ss 01:20:00 -i "C: \ Movies \ Movie.mp4" -t 00:00:20 -codec: библиотека libmp3lame -ab 128000 "D: \ output-2.mp3"
Как видите, количество аргументов командной строки и соответствующие значения одинаковы. Единственное отличие состоит в том, что параметр (начальная точка) помещается перед параметром (ввод файла) во 2-м пакетном файле. Метод называется «Поиск ввода» согласно документации FFmpeg.exe. Первый метод называется « вывода», в котором параметр (входной файл) отображается перед параметром .
В документации FFmpeg говорится, что метод поиска ввода намного быстрее, чем поиск вывода, потому что при использовании первого метода FFmpeg.exe переходит (ищет) непосредственно к указанной начальной точке во входном файле и начинает декодирование с этой точки и далее.
Принимая во внимание, что метод поиска вывода сначала открывает файл, начинает декодирование с , а затем отбрасывает данные до тех пор, пока они не достигнут Начальная точка. Таким образом, системные ресурсы (процессор, память и дисковый ввод-вывод) тратятся впустую, а время выполнения увеличивается при использовании метода поиска вывода.. СВЯЗАННЫЕ:
СВЯЗАННЫЕ:
Документация FFmpeg.exe правильная. Когда я тестировал, поиск ввода выполнялся намного быстрее, чем метод поиска вывода.
- 1-я команда (поиск по выходу) заняла 20, 48 секунды.
- Вторая команда (поиск ввода) заняла 16, 62 секунды.
Если вам известны какие-либо другие методы измерения времени выполнения процесса, сценария или команды, давайте узнаем.
Внешняя фрагментация
При внешней фрагментации у нас есть свободный блок памяти, но мы не можем назначить его процессу, потому что блоки не являются смежными.
И первая, и самая подходящая системы для распределения памяти, подверженной внешней фрагментации. Для преодоления проблемы внешней фрагментации используется уплотнение. В технике уплотнения все свободное пространство памяти объединяется и образует один большой блок. Таким образом, это пространство может быть эффективно использовано другими процессами.
Другое возможное решение внешней фрагментации — позволить логическому адресному пространству процессов быть несмежным, что позволяет процессу выделять физическую память там, где последняя доступна.
Paging:
Paging — это схема управления памятью, которая устраняет необходимость непрерывного выделения физической памяти. Эта схема позволяет физическому адресному пространству процесса быть несмежным.
- Логический адрес или виртуальный адрес (представлен в битах): адрес, генерируемый ЦП.
- Логическое адресное пространство или виртуальное адресное пространство (представленное словами или байтами): набор всех логических адресов, сгенерированных программой.
- Физический адрес (представлен в битах): адрес, фактически доступный в блоке памяти.
- Физическое адресное пространство (выраженное словами или байтами): набор всех физических адресов, соответствующих логическим адресам.
Пример:
- Если логический адрес = 31 бит, то логическое адресное пространство = 2 31слово = 2 G слов (1 G = 2 30 )
- Если логическое адресное пространство = 128 M слов = 2 7* 2 20 слов, то логический адрес = log 2 2 27 = 27 бит
- Если физический адрес = 22 бита, то физическое адресное пространство = 2 22слова = 4 M слов (1 M = 2 20 )
- Если физическое адресное пространство = 16 M слов = 2 4* 2 20 слов, то физический адрес = log 2 2 24 = 24 бита.
Преобразование виртуального адреса в физический выполняется блоком управления памятью (MMU), который является аппаратным устройством, и это преобразование известно как метод подкачки.
- Физическое адресное пространство концептуально разделено на несколько блоков фиксированного размера, называемых кадрами.
- Логическое адресное пространство также разделено на блоки фиксированного размера, называемые страницами.
- Размер страницы = Размер кадра
Рассмотрим пример:
- Физический адрес = 12 бит, тогда физическое адресное пространство = 4 К слов
- Логический адрес = 13 бит, затем логическое адресное пространство = 8 К слов
- Размер страницы = размер кадра = 1 тыс. Слов (предположение)
![]()
Адрес, генерируемый ЦП, делится на
- Номер страницы (p):количество битов, необходимых для представления страниц в логическом адресном пространстве или номер страницы.
- Смещение страницы (d):количество битов, необходимых для представления определенного слова на странице или размер страницы логического адресного пространства, или номер слова страницы или смещение страницы.
Физический адрес делится на
- Номер кадра (f):количество битов, необходимых для представления кадра физического адресного пространства или кадра номера кадра.
- Смещение кадра (d):количество битов, необходимых для представления конкретного слова в кадре, или размер кадра в физическом адресном пространстве, или номер слова кадра, или смещение кадра.
Аппаратная реализация таблицы страниц может быть выполнена с использованием выделенных регистров. Но использование регистра для таблицы страниц является удовлетворительным только в том случае, если таблица страниц мала. Если таблица страниц содержит большое количество записей, мы можем использовать TLB (буфер просмотра трансляции), специальный небольшой аппаратный кеш для быстрого просмотра.





- TLB — это ассоциативная высокоскоростная память.
- Каждая запись в TLB состоит из двух частей: тега и значения.
- Когда эта память используется, то элемент сравнивается со всеми тегами одновременно. Если элемент найден, то соответствующее значение возвращается.
![]()
Время доступа к основной памяти = м
Если таблица страниц хранится в основной памяти,
Эффективное время доступа = m (для таблицы страниц) + m (для конкретной страницы в таблице страниц)
![]()
Другие решения
Подходит для размещенных «ПК-подобных» систем. На встроенных системах код чаще всего выполняется непосредственно из флэш-памяти
Нет, это слишком упрощение, слишком много, слишком плохих учителей программирования.
Есть также много других регионов: а также куда идут все переменные со статическим хранилищем, куда идут константы и т. д.
Сегмент, в котором хранится программный код, обычно называется ,
2
Это не так просто. Обычно в основной операционной системе происходит больше всего:
в каждом потоке имеется один стек;
кучи столько, сколько вы решите выделить (на самом деле, что касается диспетчера памяти, вы просите некоторые страницы памяти «включить» в вашем виртуальном адресном пространстве, «куча» возникает из-за того факта, что обычно используются некоторые вид кода менеджера кучи для эффективного распределения этих частей памяти между выделениями);
могут быть файлы с отображенной памятью и разделяемая память;
наиболее важно, что исполняемый файл (и динамические библиотеки) отображаются в памяти процесса, обычно с зоной кода (так называемый «текстовый» сегмент), отображаемой в режиме только для чтения, и другими зонами (обычно относящимися к инициализированным глобальные и статические переменные и прочее, исправленные загрузчиком) при копировании при записи.
Итак, код хранится в соответствующем разделе исполняемого файла, который отображается в памяти.
1
Они обычно находятся в разделе под названием ,
В Linux вы можете перечислить разделы ELF-объекта или исполняемого файла с помощью команда от core-utils, например, на Исполняемый файл ELF:
1
Есть несколько сегментов памяти в дополнение к стеку и куче. Вот пример того, как программа может быть размещена в памяти:
Детали будут различаться в зависимости от платформы, но эта схема довольно распространена для систем на базе x86. Машинный код занимает собственный сегмент памяти (помечен в формате ELF), глобальные данные только для чтения будут храниться в другом сегменте ( или же ), неинициализированные глобалы в еще одном сегменте () и т. д. Некоторые сегменты доступны только для чтения, некоторые доступны для записи.
1
Ни кучи, ни стека.
Цитирование статьи в Википедии
а также
Во время выполнения сегмент кода объектного файла загружается в соответствующий сегмент кода в памяти. В частности, это не имеет никакого отношения к стеку или куче.
РЕДАКТИРОВАТЬ:
В приведенном выше фрагменте кода то, что вы испытываете, называется бесконечная рекурсия.
Даже если ваша функция не требует места в стеке для локальной переменной, она все еще нужно От себя обратный адрес из внешний функция перед вызовом внутренний функция, таким образом, требуя пространство стека, только никогда , тем самым исчерпывая пространство стека, вызывая переполнение стека.
1
Виды ошибок
Ошибки компиляции
Это простые ошибки, которые в компилируемых языках программирования выявляет компилятор (программа, которая преобразует текст на языке программирования в набор машинных кодов). Если компилятор показывает несколько ошибок, отладку кода начинают с исправления самой первой, так как она может быть причиной других.
В интерпретируемых языках (например Python) текст программы команда за командой переводится в машинный код и сразу исполняется. К моменту обнаружения ошибки часть программы уже может исполниться.
Ошибки компоновки
Ошибки связаны с разрешением внешних ссылок. Выявляет компоновщик (редактор связей) при объединении модулей программы. Простой пример — ситуация, когда требуется обращение к подпрограмме другого модуля, но при компоновке она не найдена. Ошибки также просто найти и устранить.
Ошибки выполнения (RUNTIME Error)
Ошибки, которые обнаруживают операционная система, аппаратные средства или пользователи при выполнении программы. Они считаются непредсказуемыми и проявляются после успешной компиляции и компоновки. Можно выделить четыре вида проявления таких ошибок:
- сообщение об ошибке, которую зафиксировали схемы контроля машинных команд. Это может быть переполнение разрядной сетки (когда старшие разряды результата операции не помещаются в выделенной области памяти), «деление на ноль», нарушение адресации и другие;
- сообщение об ошибке, которую зафиксировала операционная система. Она же, как правило, и документирует ошибку. Это нарушение защиты памяти, отсутствие файла с заданным именем, попытка записи на устройство, защищенное от записи;
- прекращение работы компьютера или зависание. Это и простые ошибки, которые не требуют перезагрузки компьютера, и более сложные, когда нужно выключать ПК;
- получение результатов, которые отличаются от ожидаемых. Программа работает стабильно, но выдает некорректный результат, который пользователь воспринимает за истину.
Ошибки выполнения можно разделить на три большие группы.
Ошибки определения данных или неверное определение исходных данных. Они могут появиться во время выполнения операций ввода-вывода.
К ним относятся:
- ошибки преобразования;
- ошибки данных;
- ошибки перезаписи.
Как правило, использование специальных технических средств для отладки (API-логгеров, логов операционной системы, профилировщиков и пр.) и программирование с защитой от ошибок помогает обнаружить и решить лишь часть из них.


Логические ошибки. Они могут возникать из ошибок, которые были допущены при выборе методов, разработке алгоритмов, определении структуры данных, кодировании модуля.
В эту группу входят:
- ошибки некорректного использования переменных. Сюда относятся неправильный выбор типов данных, использование индексов, выходящих за пределы определения массивов, использование переменных до присвоения переменной начального значения, нарушения соответствия типов данных;
- ошибки вычислений. Это некорректная работа с переменными, неправильное преобразование типов данных в процессе вычислений;
- ошибки взаимодействия модулей или межмодульного интерфейса. Это нарушение типов и последовательности при передаче параметров, области действия локальных и глобальных переменных, несоблюдение единства единиц измерения формальных и фактических параметров;
- неправильная реализация логики при программировании.
Ошибки накопления погрешностей. Могут возникать при неправильном округлении, игнорировании ограничений разрядной сетки, использовании приближенных методов вычислений и т.д.
4 Заключение
Первые ЭВМ использовали запоминающие устройства исключительно для хранения обрабатываемых данных. Их программы реализовывались на аппаратном уровне в виде жёстко заданных выполняемых последовательностей. Любое перепрограммирование требовало огромного объёма ручной работы по подготовке новой документации, перестройки блоков и устройств и т. д. Использование архитектуры фон Неймана, предусматривающей хранение компьютерных программ и данных в общей памяти, коренным образом переменило ситуацию.
К настоящему времени создано множество устройств, предназначенных для хранения данных. Универсального решения не существует, у каждого имеются свои достоинства и свои недостатки, поэтому компьютерные системы оснащаются несколькими видами систем хранения, основные свойства которых обуславливают их использование и назначение.
5 Литература
Организация ЭВМ. 5-е изд. /К.Хамахер, З. Вранешич, С. Заки. – СПб.: Питер; Киев: Издательская группа BHV , 2003. – 848с.
Информатика: Учебник / Под ред. проф. Н.В. Макаровой — М.: Финансы и статистика -2006. — 768 с.
За всё время развития компьютерной техники и информатики, человек смог придумать огромнейшее количество различных вещей, которые сделали компьютеры такими, какими мы их знаем сегодня. Однако компьютерная техника и информатика использует далеко не только в персональных компьютерах. На данный момент, практически любая техника, так или иначе, основана на компьютерах и информатике, которая по сути своей и является основой всего, что сейчас есть. Мы живём в мире компьютерных технологий, а значит, что простое незнание каких либо комплектующих компьютера можно принимать за неграмотность. В данном докладе мы поговорим об оперативной памяти компьютера.
Компьютер по сути своей большая коробка, с огромным количеством различных комплектующих, которые взаимодействуя между собой, создают знакомый нам компьютер. Важнейшей частью компьютера является оперативная память. Оперативная память компьютера – относится к кратковременной памяти, которую мы обсудим позже, и помогает компьютеру и его комплектующим работать в нормальном, и стабильном режиме. Если же компьютер не будет иметь оперативной памяти, то он вряд ли сможет работать, так как оперативная память один из компонентов, который обеспечивает его работу. Она очень и очень важна для компьютера, так как помогает, как и самой долговременной памяти компьютера, так и помогает процессору, и его нормальная работа вряд ли будет возможна без должного количества оперативной памяти.
Оперативная память компьютера относится к кратковременной памяти компьютера. Вообще в компьютере имеется два типа памяти, как не трудно догадаться, это кратковременная и долговременная память. Кратковременная память – помогает компьютеру работать с данными, которые он получает от других комплектующих компьютера, а потому обеспечивает стабильную работу, как и на программном уровне, так и на аппаратном.
В кратковременную память компьютер сохраняет информацию только на время работы компьютера. После же его отключения вся информация, которая была в кратковременной памяти стирается
Обычно это информации о программах и их журнала загрузок, а потому не носит особой важности даже для продвинутого пользователя. Долговременная же память хранит в себе всю ту информацию и файлы, которыми пользователь может с лёгкостью управлять, добавляя туда что-то или удаляя
Она также может храниться неограниченное время на носителе, пока пользователь сам не решит её удалить.