
Эволюционная гонка
Говоря о машинном обучении и удобных интерфейсах, мы концентрируемся на практических задачах и их решениях. Но как насчет появления «настоящей» (как у людей) эмоциональности у искусственного интеллекта? Сможет ли машина любить, грустить и злиться? «Тот факт, что мы переживаем наши собственные эмоции как „настоящие“, связан лишь с тем, что так настроена наша когнитивная система, возникшая в ходе эволюции. Особи, способные испытывать эмоции и контролировать свое поведение, получали преимущество в эволюционной гонке. Компьютеры вряд ли смогут приблизиться к моделированию реальной эволюции приматов — в этом смысле их эмоции не будут „реальными“», — полагает Мартынов.
Ключевой вопрос, говорит Мартынов: можно ли смоделировать субъективные переживания эмоций, то, что Аристотель назвал бы душой, а Декарт — cogito? Прямого ответа на этот вопрос наука до сих пор не дает, а философы собирают конференции о природе квалиа (нередуцируемых элементов субъективного опыта). Хотя есть и оптимисты вроде философа и когнитивиста Дэниела Деннета, которые утверждают, что в конечном счете субъективный опыт — это способность рассказывать себе и окружающим о том, что вы почувствовали. Убедительные вербальные отчеты об эмоциях мы, конечно, получим от машин в ближайшее время, думает Мартынов.
Но с большой вероятностью, полагает Сергей Марков, наше совместное будущее с эмоциональным искусственным интеллектом примет формы, которые невозможно вообразить сегодня со стереотипным противопоставлением людей и машин: «Скорее в будущем люди и машины будут объединены в гетерогенные синтетические системы, в которых вы уже не сможете провести даже условную черту, разделяющую человека и продукт его технологий. В таком сценарии эмоциональному интеллекту уготована большая роль».
Где нужно распознавание лиц?
Разработкой ПО для распознавания и улучшением алгоритмов занимаются программисты и дата-сайентисты. Эта технология нужна в разных сферах:
- Государство: видеоаналитика используется службами безопасности стран для пограничного контроля, а в Москве так находили нарушителей карантина. Службы безопасности организаций, имеющих дело с секретностью, также используют алгоритмы идентификации для контроля доступа сотрудников к секретным объектам.
- IT-индустрия: Microsoft, Google, Яндекс, ВКонтакте тоже разрабатывают собственные алгоритмы.
- Медицина: технология помогает выявить болезни и отслеживать прогресс в лечении.
- Банкинг: банки используют идентификацию по лицу, чтобы снять деньги в банкомате или получить кредит.
- Образование: распознавание лица помогает поймать тех, кто списывает, — сервисы подключаются к камере на компьютере студента и отслеживают его поведение и движение глаз.
- Персональные портативные устройства: на смартфонах помимо идентификации пользователя распознавание лица выполняет и развлекательную функцию — у приложений Samsung и Snapchat оно лежит в основе AR-фильтров и масок для лица.
Установка Tensorflow и Keras на Raspberry Pi 4
Перед установкой Tensorflow и Keras установим ряд необходимых библиотек:
Shell
sudo apt-get install python3-numpy
sudo apt-get install libblas-dev
sudo apt-get install liblapack-dev
sudo apt-get install python3-dev
sudo apt-get install libatlas-base-dev
sudo apt-get install gfortran
sudo apt-get install python3-setuptools
sudo apt-get install python3-scipy
sudo apt-get update
sudo apt-get install python3-h5py
|
1 |
sudo apt-getinstall python3-numpy sudo apt-getinstall libblas-dev sudo apt-getinstall liblapack-dev sudo apt-getinstall python3-dev sudo apt-getinstall libatlas-base-dev sudo apt-getinstall gfortran sudo apt-getinstall python3-setuptools sudo apt-getinstall python3-scipy sudo apt-getupdate sudo apt-getinstall python3-h5py |
Далее непосредственно установим библиотеки Tensorflow и Keras с помощью pip. Если в вашей системе используется python3 в качестве окружения по умолчанию для python, то в терминале, соответственно, необходимо использовать команду pip3.
Shell
pip3 install tensorflow
pip3 install keras
|
1 |
pip3 install tensorflow pip3 install keras |
Тест на измерение эмоционального интеллекта Д. Гоулмана
На популярном сайте testometrika.com этот тест можно пройти без регистрации. Он состоит из 10 вопросов, их вы проходите онлайн. Вам предлагается представить ситуацию и в зависимости от нее выбрать наиболее подходящий вариант ответа. Интерпретация результатов зависит от количества набранных баллов.
Но здесь есть оговорка: его можно пройти быстро, но это повлияет на точность. Например, я такая уверенная, что у меня с ЭИ все ок, прошла его и получила низкий балл. Мне методика Гоулмана “посоветовала” увеличивать самоконтроль и самомотивацию, научиться чувствовать переживания других! Буду оспаривать в следующем, более точном тесте!
Как обмануть системы распознавания лиц
Чтобы не стать жертвой некорректной работы систем распознавания, некоторые люди стараются найти способы для их обмана.
В 2017 году директор по распространению технологий «Яндекса» Григорий Бакунов разработал специальную систему макияжа, якобы помогающего обмануть нейросети. Для этого он использовал алгоритм, подбирающий образ по принципу антисходства. Примерно в том же ключе действовали участники протестов в Лондоне в 2020 году: они пытались обмануть системы распознавания лиц с помощью цветных патчей на лице.
Пост из инстаграм* the Dazzle Club
Исследователи также занимаются разработками, которые не позволяют ИИ учиться на личных данных, говорится в статье MIT Technology Review. Один из первых представленных инструментов — это программа Fawkes, которую разработала Эмили Венгер из Чикагского университета. «Мне не нравится, когда люди берут у меня то, что не должно им принадлежать», — объясняет она свою мотивацию.
Большинство подобных инструментов используют один и тот же алгоритм: они вносят в изображения небольшие изменения, которые незаметны для человеческого глаза, и заставляют ИИ неправильно определять лица на фотографиях. Этот метод очень близок к состязательной атаке, когда небольшие изменения данных могут привести модели глубокого обучения к ошибкам.
Благодаря такому подходу современные системы распознавания лиц перестанут работать. В отличие от предыдущих попыток запутать ИИ (например, нанесение краски на лица), новая технология оставляет изображения неизменными для зрительного восприятия человека. Программа Fawkes на сайте Чикагского университета для свободного скачивания и использования. С тех пор её загрузили свыше 500 тысяч раз.
Автор Fawkes Эмили Венгер и её коллеги протестировали свой инструмент на известных коммерческих системах распознавания лиц — Amazon AWS Rekognition, Microsoft Azure и Face++. В небольшом эксперименте с набором данных из 50 фотографий алгоритм был эффективен на 100 %. Позднее Fawkes не позволяла моделям, обученным на изменённых изображениях людей, распознавать эти же лица на свежих снимках. То есть небольшие изменения, внесённые в фотографии, помешали инструментам сформировать точное представление о лицах.
Видео: Emily Wenger / YouTube
Fawkes может помешать новой системе распознавания определять людей по фото. Но у программы не получится противодействовать существующим системам, которые уже были обучены на незащищённых изображениях. Впрочем, технология постоянно совершенствуется.
Создатель Fawkes считает, что инструмент LowKey, разработанный Валерией Черепановой и ее коллегами из Университета Мэриленда, может решить эту проблему. LowKey расширяет возможности Fawkes: он противодействует системам, основанным на более сильном виде состязательной атаки, а также обманывает предварительно обученные коммерческие модели. Как и Fawkes, LowKey доступен как веб-сервис.
Большинство подобных инструментов, включая Fawkes, используют один и тот же базовый подход: в изображение вносятся микроизменения, которые трудно заметить человеческим глазом, но они нарушают работу ИИ. В частности, если дать Fawkes на ввод серию фотографий, он добавит к ним искажения на уровне пикселей, которые не позволят современным системам распознавания лиц определить, кто изображён на снимках.
Намеренное «загрязнение» данных может затруднить для компаний тренировку моделей машинного обучения, предположил директор по продуктам компании Ivideon Заур Абуталимов в разговоре со Skillbox Media.
«Однако отличием этих новых методов является то, что они работают с фотографиями одного человека. Такие инструменты, как Fawkes, могут помешать новой системе распознавания лиц распознать именно вас, но они не помешают существующим системам, которые уже обучались на ваших „незащищённых“ изображениях», — подчеркнул Заур Абуталимов.
Преподаватель Deep Learning School, автор блога об искусственном интеллекте и нейронных сетях Татьяна Гайнцева рассказала Skillbox Media, что инструменты Fawkes и LowKey могут быть перспективными, но не стоит ожидать от них абсолютной эффективности.
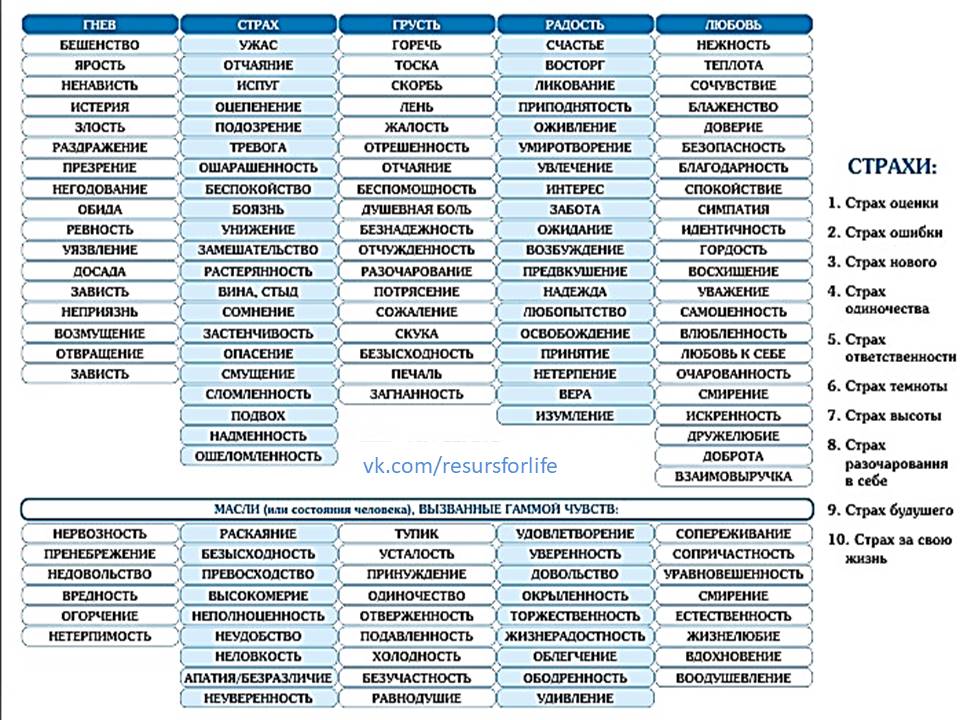
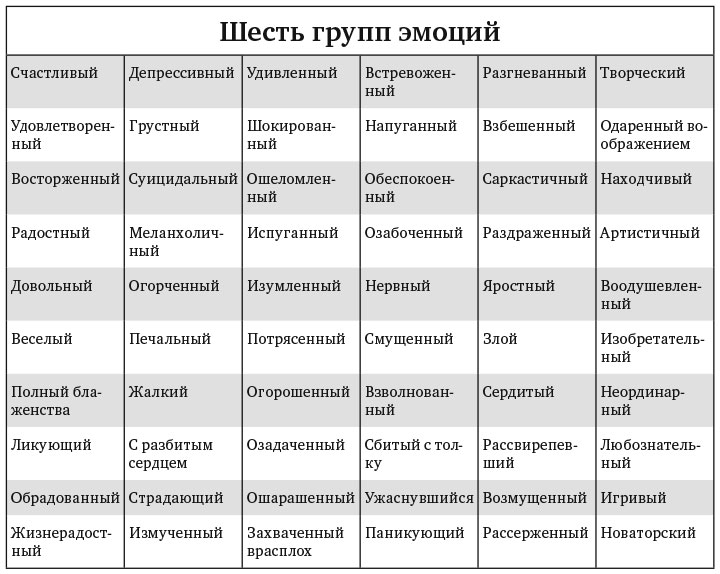
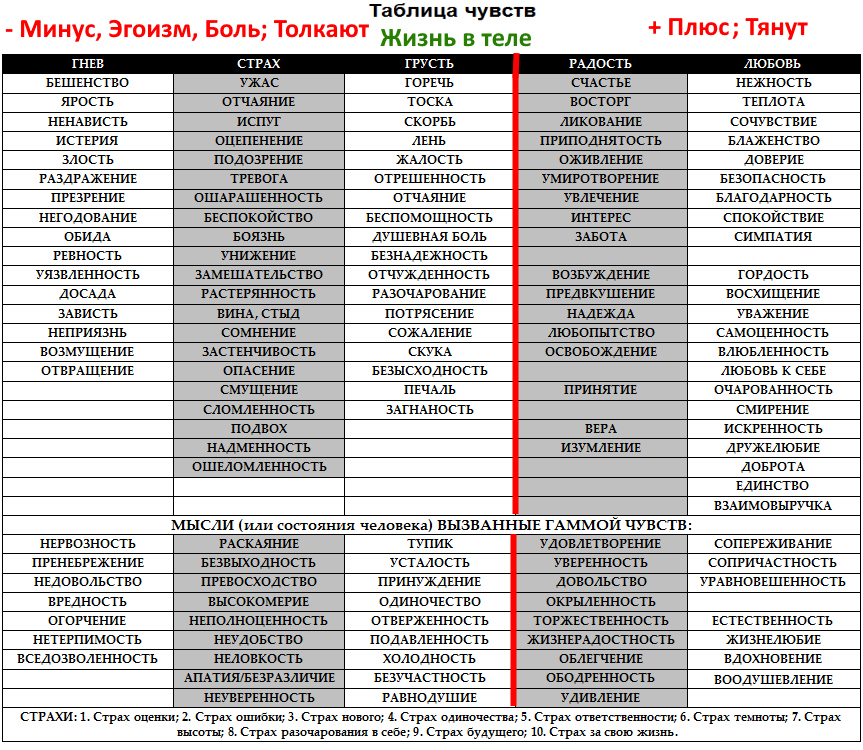
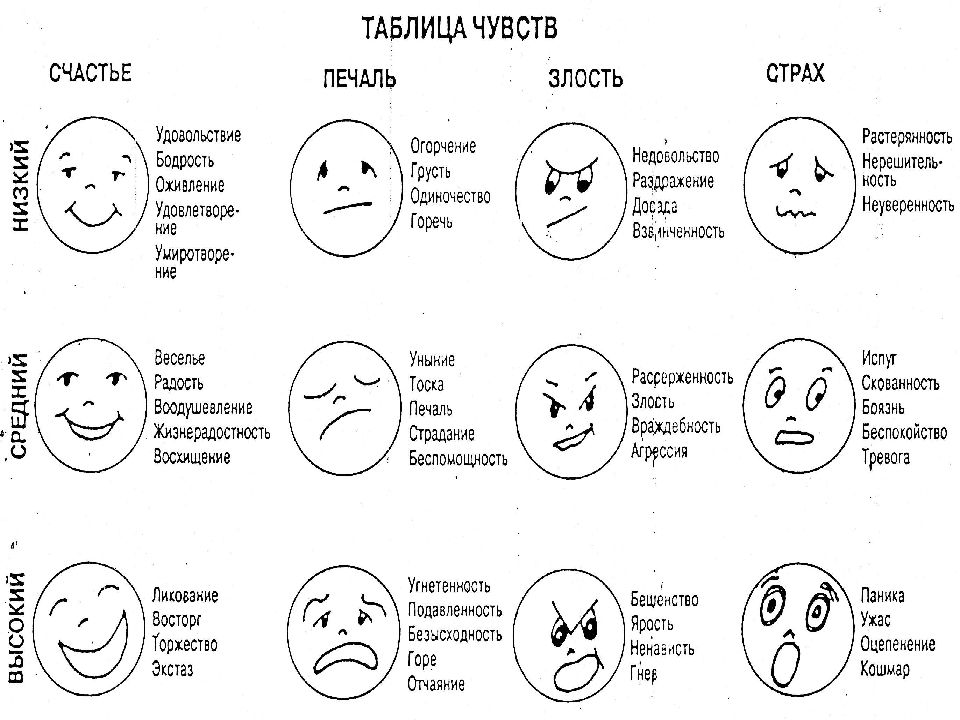
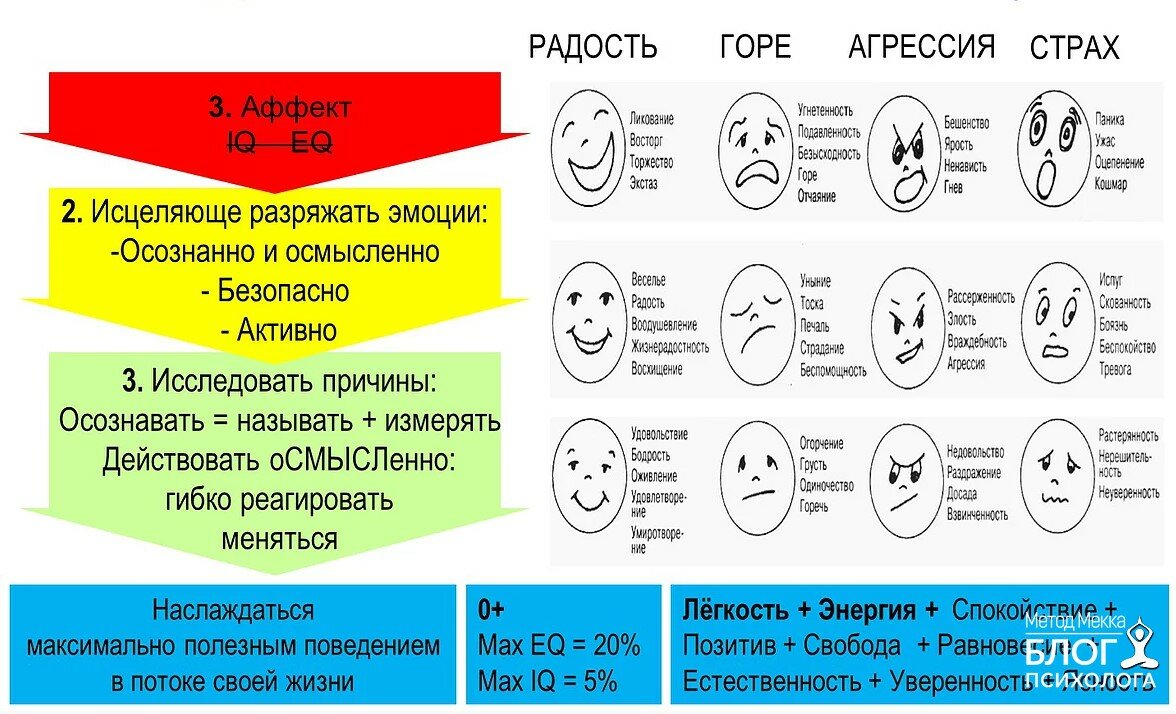
Что мы знаем об эмоциях?
Первые шаги в изучении эмоций были сделаны в середине XIX века — французский невролог Гийом Дюшен был первым исследователем по физиологии эмоций. Его работы по стимуляции лицевых мышц человека электрическими разрядами оказали существенное влияние на появление книги «The Expression of Emotion in Man and Animals» авторства Чарльза Дарвина, который заявил, что эмоции на лице человека являются универсальными.
Спустя два столетия Рэй Бердвистел стал основоположником кинесики (науки о невербальном поведении человека). А уже наш современник Пол Экман, всемирно признанный эксперт по психологии эмоций (известен как прототип главного героя сериала «Обмани меня»), разработал критерии для описания эмоций.
Усложняем тесты
![]()
Я загрузил вместо фото — рисунок. Видим, что был найден только один персонаж. Мне кажется, счастье этого малыша переоценено программой (0.76). На мой взгляд, это больше Нейтральное выражение лица.
![]()
Черно-белое фотографическое изображение Гитлера. Что это? Он щурится от солнца или действительно так зол? Программа тоже сомневается : ярость (0.55) + отвращение (0.27). Пожалуй, я соглашусь с вердиктом.
![]()
Уил Смит удивлен (0.99) способностям алгоритма. Думаю, как актер он способен на любое выражение лица.







Алгоритму не важна ни раса, ни возраст персонажа (я вообще то, ещё и Эйнштейна прогонял с его высунутым языком).
Ограничения ИИ
![]()
У ИИ сложности с тремя вещами: эмоциональными нюансами, созданием оригинального контента и моральными нормами
1. Плохо понимает эмоциональные нюансы
На протяжении всей истории люди использовали эмоции как механизм выживания (пример: страх помогает уберечь себя от угрозы). Человек может узнать эмоции других по телодвижениям, тону голоса, контексту ситуации и социальным сигналам. Общаясь с другими и осваивая культурные нормы, мы учились понимать эмоции.
В отличии от нас, ИИ не может чувствовать, и он не жил долгие годы среди людей. Ему трудно понять эмоциональные тонкости.
В 2017 году учёный Джанелл Шейн пыталась научить нейросеть строить фразы для пикапа. Для этого она загрузила в компьютер тысячи фраз, с которых можно начать знакомство.
Нейросеть так и не смогла освоить этот навык. Вот примеры того, что она выдавала:
Даже самым красноречивым людям флирт даётся непросто. Из эксперимента Шейл ясно, что научить распознавать или выражать тонкие эмоциональные нюансы машину — тем более сложная задача.
2. Не может создать оригинальный контент
![]()
Эту серию портретов написал искусственный интеллект, обученный Марио Клингеманном
Машина использовала алгоритм распознавания лиц, чтобы нарисовать картины. ИИ усвоил паттерны и в процессе работы основывался на них. Есть ли у этих картин эмоциональное наполнение и художественная ценность — большой вопрос. Но для того, чтобы машина смогла их сделать, пришлось загрузить огромные массивы данных с изображениями от технических компаний, музеев и других организаций.
3. Не понимает нормы морали
![]()
Пример ошибки алгоритма распознавания изображений. Он пометил чернокожих как горилл
ИИ учится только на данных, которые подаются в систему. Темнокожий Джеки Алсин узнал это на собственном опыте: приложение для фотографий пометило его и его друга как «горилл». Судя по всему, расистские шутки повлияли на выбор алгоритмом категории.
Проблема в том, что машинам трудно привить понятие морали. Люди не могут передать мораль объективно, в измеримых показателях, которые компьютер умеет обрабатывать. У ИИ нет собственного морального и социального сознания, поэтому он не может фильтровать входящие данные, опираясь на этику.
Это был раздел с недостатками ИИ. Теперь поговорим о том, в чём машины лучше людей.
![]()
ИИ хорошо умеет персонализировать контент, работать с множеством переменных сразу и создавать вариации
1. Динамическая персонализация
![]()
Контент, который предлагает Instagram, подбирается под пользователя и меняется в зависимости от его действий
Вспомните, что происходит, когда вы знакомитесь с человеком. Вы неосознанно начинаете судить о нём, основываясь на внешности и манерах.
ИИ делает то же самое, но принимает во внимание подсознательный выбор человека. Например, фид в Instagram меняется (динамически персонализируется) в зависимости от многих вещей: времени суток, лайкнутых постов, постов, на которых вы задержались, интересов друзей, модных трендов, местоположения и типа устройства, которым вы пользуетесь
2. Обработка нескольких переменных одновременно
![]()
По словам Huffington Post , сегодня врачам нужно тратить около 160 часов в неделю на чтение научных статей, чтобы обновлять медицинские знания.
Машины же отлично обрабатывают сотни элементов данных одновременно. Например, IBM Watson AI может поставить диагноз быстрее и точнее, чем человек. Watson способен просмотреть более 600 000 медицинских заключений, 2 миллиона страниц медицинских журналов и найти до 1,5 миллионов карт пациентов — объём знаний, который не может удержать в голове ни один врач. В результате IBM Watson может точно диагностировать рак лёгких в 90% случаев в отличии от врачей-людей (те могут лишь в 50%).
3. Создавать вариации
![]()
Варианты упаковки Nutella Unica
Как только ИИ распознаёт паттерн, он может мгновенного сгенерировать несколько вариаций. В проекте под названием «Nutella Unica» алгоритм, опираясь на базу данных паттернов и цветов, создал семь миллионов разных версий упаковки Nutella.
Тест на оценку эмоционального интеллекта (ЭмИн) Люсина Д. В.
Это профессиональная психодиагностическая методика – первая в российской психологии. Она разработана на авторскую модель EQ, которую разработал российский психолог Люсин. Методика имеет свою структуру: понимание эмоций (ПЭ) и управление эмоциями (УЭ). Описание методики Люсина: опросник содержит 46 утверждений, которые оцениваются по 4-балльной шкале (согласен-несогласен).








Все утверждения объединяются в 5 субшкал, по которым и проверяется ваш уровень EQ. По мнению автора, Emotional Quotient определяется по тому, насколько у человека развиты способности к пониманию и управлению эмоциями, определению эмоций других и влиянию на окружающих.
Что нужно понимать о нейросетях
Нейросети в современном виде — это машины по обработке чисел. Нейросеть не понимает, что смотрит на картинку или водит машинку, — она лишь видит числа на входе и выдаёт числа на выходе. Она даже не знает, что у её чисел на выходе для нас есть какое-то значение.
Например, в этом видео нейросеть получает семь чисел на входе (это расстояния до препятствий и направление движения) и выдает два числа на выходе — поворот руля и газ-тормоз. И уже симулятор гоночной игры превращает эти числа в движение машинки. Нейронка просто обрабатывает числа:
Нейросеть всё еще не умеет импровизировать. Она может действовать в ситуации некоторой непредсказуемости, но генерировать оригинальные решения — нет.
Нейросеть можно запустить на любом компьютере, особое железо не нужно. Это просто алгоритм и данные. Их можно скопировать, заархивировать и выложить в интернет.
При этом есть и специальное железо — нейронные процессоры или, по-другому, ИИ-ускорители. Это те же микропроцессоры, но соединённые таким образом, чтобы быстрее обсчитывать именно нейронки. Но они нужны только для скорости, так-то принципиально нейронку можно рассчитать и на обычном процессоре.
На нынешнем витке развития нейросети способны лишь воспроизводить то, чему их научили. Свободное творчество с чистого листа пока не изобрели.
Рынок технологий распознавания эмоций — что с ним?
Он есть, но он молод, у него ещё всё впереди.
Сейчас рынок детекции эмоций переживает бум и по оценке западных специалистов к 2021 году он вырастет, по разным подсчетам, от $19 млрд до $37 млрд.
Так, по мнению влиятельного агентства MarketsandMarkets, глобальный объём рынка эмоций в 2016 году составил $6,72 млрд, и предполагается, что к середине 2020-х годах он увеличится до $36,07 млрд. Рынок эмоциональных технологий не монополизирован. Тут найдётся место и для корпораций, и для лабораторий, и для стартапов. Более того, нормальная рыночная практика: корпорации интегрируют в свои решения наработки компаний поменьше.
Эмоциональные и поведенческие технологии востребованы в различных сферах, включая медицинскую.
Обращаясь к зарубежному опыту, вспомним, как компания Empatica под руководством Розалинд Пикард первой в мире получила разрешение от надзорных органов США, ответственных за клинические испытания (FDA-клиринг), на использование их носимого браслета Embrace, который не только фиксирует физиологические данные о состоянии владельца, но и оценивает его эмоциональный фон и предсказывает вероятность наступления сложных для организма ситуаций. Это может помочь людям с расстройствами аутистического спектра, депрессией и в сложных случаях в неврологии и медицине.
Израильская компания Beyond Verbal совместно с Mayo Clinic ищет в голосе человека вокальные биомаркеры, по которым определяются не только эмоции, но и закладывается возможность прогнозирования аортокоронарных заболеваний, болезней Паркинсона и Альцгеймера, что уже подводит эмоциональную проблематику к теме геронтологии и поиску путей замедления старения.
Если говорить о применимости технологий, то тут преимущественно задействована b2b-сфера в секторах вроде интеллектуального транспорта, ритейла, рекламы, HR, IoT, gaming.
Но и в b2c тоже есть спрос: EaaS (Emotion as a Service) или же облачное аналитическое решение (Human data analytics) позволит любому пользователю загружать видеофайл и получать по нему всю эмоциональную и поведенческую статистику для каждого фрагмента записи.
О востребованных профессиях в сфере искусственного интеллекта
Кадров катастрофически не хватает, их дефицит огромен во всём мире. И, к сожалению, пока ещё образование отстаёт, потому что область стремительно развивается. Как это часто бывает, за любой развивающийся областью тяжело успеть образованию. Пока ты разрабатываешь программу обучения, находишь специалистов, всё это дело убегает, и фактически в нашей области можно что-то делать и успевать, только если ты учишься у действующих специалистов, которые прямо сейчас на передовой.
Что касается фундаментальных знаний математики, алгоритмов, искусственном интеллекте, то здесь на территории наших стран всё более или менее хорошо. Что касается получения довеска – свежего актуального опыта и знаний, здесь, конечно, плохо, но с этим нужно бороться. В «Яндексе» мы боремся по мере своих сил и возможностей, у нас создана школа анализа данных, где мы обучаем специалистов по машинному обучению, и там преподают действующие сотрудники, и не только наши, учёные, которые прямо сейчас этим занимаются. Отчасти компенсируют проблему с образованием появляющиеся курсы, велики возможности онлайн-образования. Но нельзя ничему человека научить – ему можно помочь научиться. Машинное обучение, искусственный интеллект – научиться ему трудно, нужно прикладывать серьёзные усилия, но возможности есть. Есть и школы анализа данных, и курсы, и большое количество информации в интернете. Есть множество технических вузов, которые дают фундамент, необходимый и достаточный для того, чтобы дальше проходить все остальные круги. И когда у тебя есть фундамент, ты можешь на нём построить и положить кирпичики дополнительных сверхсовременных знаний и выстроить свои навыки, свою квалификацию.
Что такое распознавание лиц?
Итак, в создании алгоритмов обнаружения лиц мы (люди) преуспели. А можно ли также распознавать, чьи это лица?
Распознавание лиц — это метод идентификации или подтверждения личности человека по его лицу. Существуют различные алгоритмы распознавания лиц, но их точность может различаться. Здесь мы собираемся описать распознавание лиц при помощи глубокого обучения.
Итак, давайте разберемся, как мы распознаем лица при помощи глубокого обучения. Для начала мы производим преобразование, или, иными словами, эмбеддинг (embedding), изображения лица в числовой вектор. Это также называется глубоким метрическим обучением.
Для облегчения понимания давайте разобьем весь процесс на три простых шага:
Обнаружение лиц
Наша первая задача — это обнаружение лиц на изображении или в видеопотоке. Далее, когда мы знаем точное местоположение или координаты лица, мы берем это лицо для дальнейшей обработки.
Извлечение признаков
Вырезав лицо из изображения, мы должны извлечь из него характерные черты. Для этого мы будем использовать процедуру под названием эмбеддинг.
Нейронная сеть принимает на вход изображение, а на выходе возвращает числовой вектор, характеризующий основные признаки данного лица. (Более подробно об этом рассказано, например, в нашей серии статей про сверточные нейронные сети — прим. переводчика). В машинном обучении данный вектор как раз и называется эмбеддингом.
Теперь давайте разберемся, как это помогает в распознавании лиц разных людей.
Во время обучения нейронная сеть учится выдавать близкие векторы для лиц, которые выглядят похожими друг на друга.
Например, если у вас есть несколько изображений вашего лица в разные моменты времени, то естественно, что некоторые черты лица могут меняться, но все же незначительно. Таким образом, векторы этих изображений будут очень близки в векторном пространстве. Чтобы получить общее представление об этом, взгляните на график:
Чтобы определять лица одного и того же человека, сеть будет учиться выводить векторы, находящиеся рядом в векторном пространстве. После обучения эти векторы трансформируются следующим образом:
Здесь мы не будем заниматься обучением подобной сети. Это требует значительных вычислительных мощностей и большого объема размеченных данных. Вместо этого мы используем уже предобученную Дэвисом Кингом нейронную сеть. Она обучалась приблизительно на 3000000 изображений. Эта сеть выдает вектор длиной 128 чисел, который и определяет основные черты лица.









Познакомившись с принципами работы подобных сетей, давайте посмотрим, как мы будем использовать такую сеть для наших собственных данных.
Мы передадим все наши изображения в эту предобученную сеть, получим соответствующие вектора (эмбеддинги) и затем сохраним их в файл для следующего шага.
![]()
Наш телеграм канал с тестами по Python, задачами с собеседований и разбором решений.
Посмотреть
×
Сравнение лиц
Теперь, когда у нас есть вектор (эмбеддинг) для каждого лица из нашей базы данных, нам нужно научиться распознавать лица из новых изображений. Таким образом, нам нужно, как и раньше, вычислить вектор для нового лица, а затем сравнить его с уже имеющимися векторами. Мы сможем распознать лицо, если оно похоже на одно из лиц, уже имеющихся в нашей базе данных. Это означает, что их вектора будут расположены вблизи друг от друга, как показано на примере ниже:
Итак, мы передали в сеть две фотографии, одна Владимира Путина, другая Джорджа Буша. Для изображений Буша у нас были вектора (эмбеддинги), а для Путина ничего не было. Таким образом, когда мы сравнили эмбеддинг нового изображения Буша, он был близок с уже имеющимися векторам,и и мы распознали его. А вот изображений Путина в нашей базе не было, поэтому распознать его не удалось.
Бесплатный курс по технологиям искусственного интеллекта от GeekBrains для новичков
Бесплатные занятия понравятся всем, кому интересна сфера машинного обучения, кто хотел бы дальше развиваться в этом направлении и больше узнать про ИИ. Ведь он, на самом деле, необычайно многообразен и необычные задачи смогут открыться каждому.
На занятиях вы сможете узнать, как начать свою работу в ИИ, устройство проектов данной сферы, и то, какие задачи решают разные направления машинного обучения. Вам будет доступен разбор практических кейсов под руководством настоящих экспертов.
Спикер: Юлия Пономарёва, Machine Learning Engineer в компании Napoleon IT. Она работает в отделе компьютерного зрения, её последний проект — разработка системы распознавания текста прайс-листов. Юлия является выпускницей Высшей школы электроники и компьютерных наук ЮУрГУ.
- Профессии в машинном обучении.
- Области искусственного интеллекта и их различия.
- Классический Machine Learning: классификация, регрессия, рекомендательные системы.
- Обработка естественного языка (NLP): классификация, генерация, вопросно-ответные системы, суммаризация, машинный перевод.
- Компьютерное зрение (CV): классификация, детекция, сегментация, OCR, трекинг, генерация.
В настоящее время происходит подъем технологий искусственного интеллекта, каждому дан шанс создать что-то невероятное и интригующее, полезное и серьезное, при этом не требуются какие-то сверхсекретные технологии и недоступная аппаратура. Требуется мало: современная видеокарта и неугасаемый энтузиазм со жгучим желанием творить.
Возможно, что именно вы совершите прорыв в этой сфере и оставите о себе память в истории современных технологий искусственного интеллекта.
*Facebook — организация, деятельность которой признана экстремистской на территории Российской Федерации.